The total solar eclipse on April 8, 2024, coincides with an exciting time for wild birds. Local birds are singing for mates and fighting for territories as they gear up for their once-a-year chance to breed.
Tens of millions of migrating birds will be passing through the path of totality, and they mostly migrate at night.
Because birds use light to match their behaviors to their environment, scientists like us have lots of questions about how they will respond to the eclipse. Will they pause their fighting and wooing and shift toward bedtime-like behaviors? How about a nocturnal animal like an owl or those nighttime migrants – will they start to rustle from their roosts before they realize it's not night?
As behavioral biologists at Indiana University, we research wild breeding birds, with a goal of understanding why animals behave the way that they do in response to environmental challenges and opportunities. For the 2024 eclipse, our team is launching a new project and developing an app. If everything goes as planned, we should end up with a large dataset after the eclipse, collected by community scientist volunteers across the country.
There's an app for that
On average, a total solar eclipse occurs in the same place only once every 375 years. Most wild animals, like most people, have never seen the sky quickly switch to night in the middle of the day. These rare events are a natural experiment that can help scientists like us understand how animals respond to an unusual sudden change in light.
NASA
Most past research on animal behavior during total solar eclipses is anecdotal. Observers have reported that zoo animals acted distressed or went into their enclosures. Scientists have spotted spiders starting the nightly deconstruction of their webs in the middle of the day, and farmers have heard their roosters start to crow after totality, as if it's once again dawn. Other reports suggest more subtle effects on animal behavior.
Massive amounts of standardized data can help to make sense of these observations. But because totality covers such a large swath of the globe in a short amount of time, it would be impossible for one scientist or even one small team to get enough observations to figure out why some animals respond more strongly to a solar eclipse than others.
With collaborators across our campus – including Jo Anne Tracey at the Office of Science Outreach and Paul Macklin at Indiana University's Luddy School of Informatics, Computing, and Engineering – we have created an app called SolarBird.
Anyone can download SolarBird for free in the Apple Store and Google Play. The app asks participants to find a bird and watch it or listen to it for 30 seconds, while clicking a few prompts on what the bird does before, during and after totality. You don't need to have any prior knowledge or bird expertise to participate.
These types of public science projects have aided lots of scientific discoveries, and we are hoping the public can help us learn more about bird behavior during an eclipse, too. Anyone can help. Even observations outside of totality collect important baseline data.
Technology and bird behavior
Apps like Solarbird aren't the only technologies that help researchers observe more than what any one individual scientist can see or hear.
For example, during the August 2017 solar eclipse, researchers collected data from weather stations across the United States, including several sites along the path of totality. Like the weather forecaster on your local news channel, they used radar to detect movement in the skies, but instead of clouds, they focused on the radar signatures of flying insects and birds.
The team saw some changes in activity – mainly, the birds didn't follow their typical daytime activity patterns as much, but they saw no consistent increase in night-like activity. Because they used radar, it's not clear exactly which bird behaviors increased or decreased.
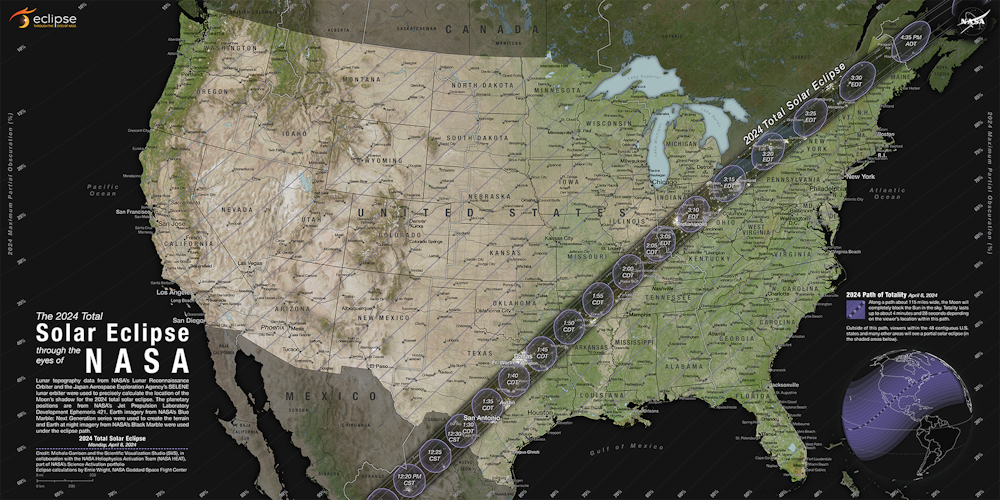
The April 2024 eclipse will last longer than 2017's, with four full minutes of darkness. And, with spring in high gear, birds are singing up a storm.
Bird songs generally convey two critical messages: “keep away” to a rival and “come here” to a prospective mate. Singing is also really easy for observers to notice. Most birds sing at 85 decibels, measured at 3 feet (1 meter) away. That's the equivalent of a power mower – loud enough to notice that it's happening or that it's suddenly stopped, even across your yard or a public park.
With Dustin Reichard from Ohio Wesleyan University, our team has put out passive audio recorders to record how the eclipse affects birds' singing.
Researchers tracking wildlife have used autonomous recording units for years. These army-green, weatherproof devices are about the size of a Kleenex box, and typically strapped to a tree while they record virtually anything within earshot. We have 20 of them out now, at rural, suburban and urban sites.

National Parks Service
Software advances help to automate the process of identifying bird songs by species with less work on the human end. We started recording the last week of March to collect song rates at a typical dawn and a typical dusk. We also measured important controls like how much birds normally sing at at 3:06 PM, the peak of totality here in Bloomington, Indiana.
We hope to use these recordings to figure out why some animals might be more or less affected by a solar eclipse.
For example, artificial light at night can affect bird physiology, behavior and abundance, and the total solar eclipse gives us a new way to test how light pollution affects behavior.
Urban birds may have gotten used to odd changes in light. Forest dwellers might differ from grassland birds, based on the amount of light in their natural habitat. Or, social species might increase their alarm calls, which would give insight into how animals use social bonds to navigate the unknown.
If you're in the path of totality this April, be sure to take in the celestial show. But you may also want to look around and listen for birds, insects and other wildlife to see how they're responding to this once-in-a-lifetime moment.